
Cuando solo usa ASCII, ¿cómo puede representar cosas más complejas como emoticonos o caracteres no latinos? Una respuesta es Punycode, que es una forma de representar caracteres Unicode en ASCII. Sin embargo, técnicamente puede codificar los bits sin procesar de Unicode como caracteres, como Básico64, Hay un problema. El DNS (Sistema de nombres de dominio) generalmente requiere que los nombres de host no distingan entre mayúsculas y minúsculas, por lo que si escribe HACKADAY.com, HackADay.com o simplemente hackaday.com, todo va al mismo lugar.
[A. Costello] En la Universidad de California, Berkley, propuso la idea de Punycode en RFC 3492 en marzo de 2003. Describe un algoritmo simple donde todos los caracteres ASCII regulares se extraen y se adjuntan a un lado por un separador, en este caso un guión. Luego, los caracteres Unicode se codifican y se agregan al final de la cadena.
Primero, el punto de código numérico y la posición en la cadena se multiplican juntos. Entonces el número se codifica como Fondo-36 (az y 0-9) entero de longitud variable. Por ejemplo, el saludo y el griego gracias, “Hola gracias” voluntad “Hola, -mxahn5algcq2″. También una ciudad hermosa Munich vendrá mnchen-3ya.
Como puede notar en el ejemplo griego, no hay nada que ayude al decodificador a saber cuál de los 36 caracteres base pertenece a cuál de los símbolos Unicode originales. Con enteros de longitud variable, cada dígito significativo es reconocible porque hay un umbral para qué dígitos se pueden codificar. Una máquina de estados finitos viene al rescate. El RFC proporciona un pseudocódigo de ejemplo que describe el algoritmo. Es bastante inteligente y utiliza un sesgo que rota a medida que avanza la decodificación. Dado que aumenta constantemente, es una función monótona con algunas propiedades inteligentes.
Por supuesto, las URL tienen un prefijo especial en minúsculas para que las URL normales no se interpreten como códigos en minúsculas. xn-- le dice al navegador que es código. Esto incluye todos los caracteres Unicode, por lo que los emojis también son válidos. Entonces, ¿por qué no puedes ir? xn--mnchen-3ya.de? Si lo escribe en su navegador o hace clic en el enlace, es posible que su navegador convierta ese confuso revoltijo de letras en una bonita URL (no todos los navegadores hacen esto). El mayor problema es el propio Unicode.
Si bien Unicode ofrece un soporte increíble para habilitar los cientos de idiomas que se usan en Internet todos los días, y nos atrevemos a decir incluso los bastante sencillos, hay algunas verrugas. El cirílico, las letras de ancho cero y otras peculiaridades de Unicode permiten a aquellos con malas intenciones configurar un dominio que, cuando se representa aparece como un sitio web conocido. Los certificados SSL son válidos y todo lo demás está comprobado. El alfabeto cirílico tiene caracteres que se ven visualmente similares a sus contrapartes latinas, pero se representan de manera diferente. Las oportunidades para los piratas informáticos y las empresas de phishing son demasiado grandes y, hasta ahora, los punycodes no están permitidos en la mayoría de los dominios.
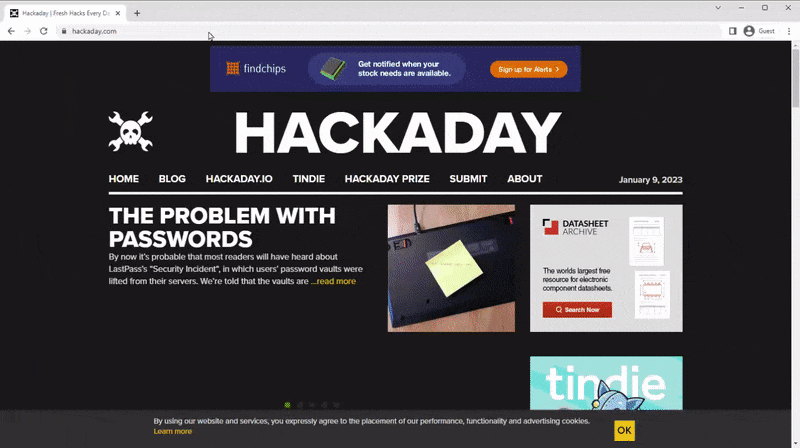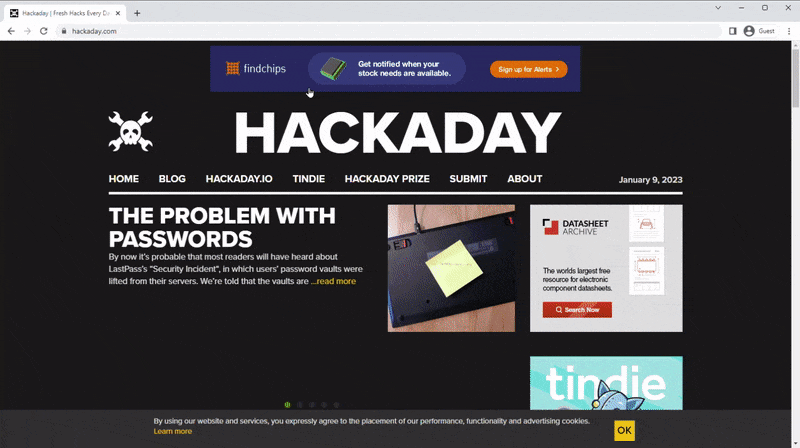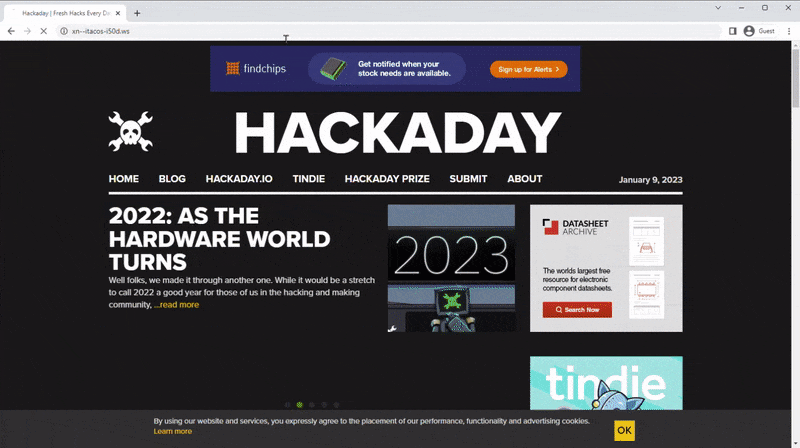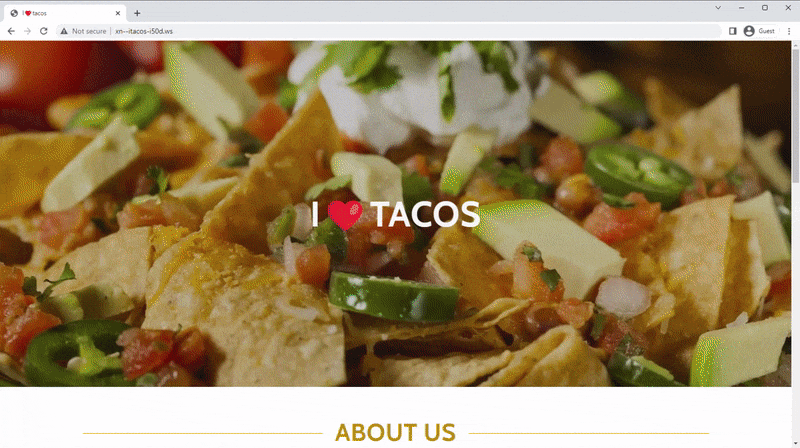
Por ejemplo, ¿puedes notar la diferencia entre estos dos dominios?
Algunos navegadores muestran el texto del mouse como Punycode, mientras que otros lo conservan como su equivalente UTF-8. La “a” (U+0061) ha sido reemplazada por una “a” cirílica (U+0430), que la mayoría de las computadoras hacen exactamente con el mismo carácter.
este es Ataque de homógrafos de IDN, donde confían en que el usuario haga clic en un enlace que no pueden diferenciar. En 2001, dos investigadores de seguridad publicaron un artículo sobre el tema, registrando “microsoft.com” en letras cirílicas como prueba de concepto. En respuesta, se recomendó a los dominios de nivel superior que aceptaran solo caracteres Unicode que contengan caracteres latinos y caracteres de los idiomas utilizados en ese país. Como resultado, muchos dominios comunes de nivel superior basados en EE. UU. no aceptan dominios Unicode en absoluto. Al menos los caracteres que no se muestran están vinculados específicamente a la ICANN, lo que evita una gran lata de gusanos, pero tener caracteres visualmente idénticos pero ligeramente diferentes es confuso.
Sin embargo, se están introduciendo lentamente mitigaciones para este tipo de ataques. Como primera capa de protección, los navegadores basados en Firefox y Chromium solo mostrarán la versión que no sea Punycode si todos los caracteres son del mismo idioma. Algunos navegadores convierten todas las URL de Unicode a Punycode. Otras tecnologías utilizan el reconocimiento óptico de caracteres (OCR) para determinar si una URL se puede interpretar de forma diferente. Es posible que los enlaces enviados por SMS o correo electrónico fuera del navegador no tengan la misma inteligencia, y no lo sabrá hasta que los abra en su navegador. Y entonces es demasiado tarde.
Dejando a un lado los desafíos, ¿los Punycodes tendrán su tiempo bajo el sol? ¿Hackaday alguna vez obtendrá ☠️📅.com? Quién sabe. Pero mientras tanto, podemos disfrutar de una solución inteligente propuesta en 2003 al complicado problema de la internacionalización de dominios que aún no hemos resuelto por completo.

Especialista web. Evangelista de viajes. Alborotador. Fanático de la música amigable con los hipster. Experto en comida




